在 Roo Code 中使用 LiteLLM
LiteLLM 是一个多功能工具,通过提供统一的 OpenAI 兼容 API,可以访问超过 100 种大型语言模型(LLM)。这允许您运行本地服务器,将请求代理到各种模型提供商或提供本地模型,所有这些都可以通过一致的 API 端点访问。
官网: https://litellm.ai/(主项目)& https://docs.litellm.ai/(文档)
主要优势
- 统一 API: 通过单一的 OpenAI 兼容 API 访问各种 LLM(来自 OpenAI、Anthropic、Cohere、HuggingFace 等)。
- 本地部署: 在本地运行自己的 LiteLLM 服务器,让您更好地控制模型访问并可能降低延迟。
- 简化配置: 在一处(您的 LiteLLM 服务器)管理凭据和模型配置,让 Roo Code 连接到它。
- 成本管理: LiteLLM 提供跨不同模型和提供商跟踪成本的功能。
设置您的 LiteLLM 服务器
要在 Roo Code 中使用 LiteLLM,您首先需要设置并运行 LiteLLM 服务器。
安装
- 安装支持代理的 LiteLLM:
pip install 'litellm[proxy]'
配置
- 创建配置文件(
config.yaml)来定义您的模型和提供商:model_list:
# 配置 Anthropic 模型
- model_name: claude-sonnet
litellm_params:
model: anthropic/claude-sonnet-model-id
api_key: os.environ/ANTHROPIC_API_KEY
# 配置 OpenAI 模型
- model_name: gpt-model
litellm_params:
model: openai/gpt-model-id
api_key: os.environ/OPENAI_API_KEY
# 配置 Azure OpenAI
- model_name: azure-model
litellm_params:
model: azure/my-deployment-name
api_base: https://your-resource.openai.azure.com/
api_version: "2023-05-15"
api_key: os.environ/AZURE_API_KEY
启动服务器
-
启动 LiteLLM 代理服务器:
# 使用配置文件(推荐)
litellm --config config.yaml
# 或快速启动单个模型
export ANTHROPIC_API_KEY=your-anthropic-key
litellm --model anthropic/claude-model-id -
代理默认在
http://0.0.0.0:4000运行(可通过http://localhost:4000访问)。- 您也可以为 LiteLLM 服务器本身配置 API 密钥以增加安全性。
有关高级服务器配置和功能的详细说明,请参考 LiteLLM 文档。
在 Roo Code 中的配置
LiteLLM 服务器运行后,您有两种方式在 Roo Code 中配置它:
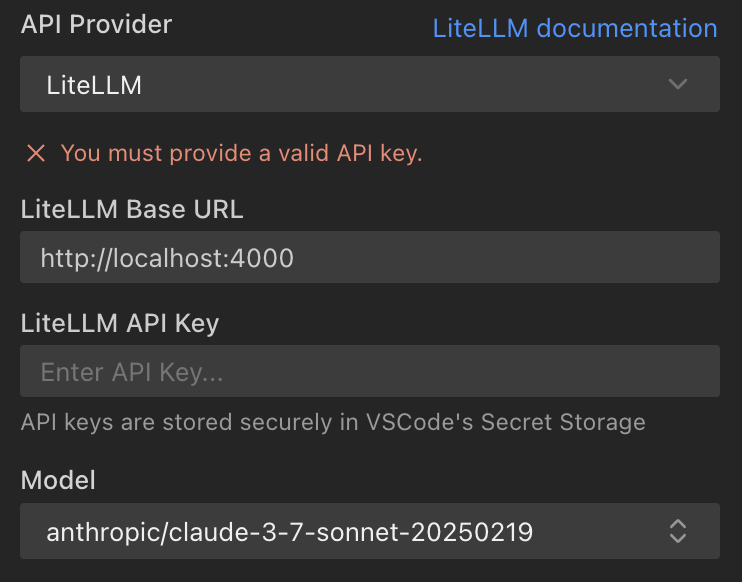
选项 1:使用 LiteLLM 提供商(推荐)
- 打开 Roo Code 设置: 点击 Roo Code 面板中的齿轮图标()。
- 选择提供商: 从“API Provider”下拉菜单中选择“LiteLLM”。
- 输入基础 URL:
- 输入您的 LiteLLM 服务器 URL。
- 如果留空,默认为
http://localhost:4000。
- 输入 API 密钥(可选):
- 如果您为 LiteLLM 服务器配置了 API 密钥,请在此处输入。
- 如果您的 LiteLLM 服务器不需要 API 密钥,Roo Code 将使用默认的虚拟密钥(
"dummy-key"),这应该可以正常工作。
- 选择模型:
- Roo Code 将尝试通过查询
${baseUrl}/v1/model/info端点从您的 LiteLLM 服务器获取可用模型列表。 - 下拉菜单中显示的模型来自此端点。
- 如果您在 LiteLLM 服务器中添加了新模型,可以使用刷新按钮更新模型列表。
- 如果未选择模型,Roo Code 将使用默认模型。确保您至少在 LiteLLM 服务器上配置了一个模型。
- Roo Code 将尝试通过查询
选项 2:使用 OpenAI 兼容提供商
或者,您可以使用“OpenAI Compatible”提供商配置 LiteLLM:
- 打开 Roo Code 设置: 点击 Roo Code 面板中的齿轮图标()。
- 选择提供商: 从“API Provider”下拉菜单中选择“OpenAI Compatible”。
- 输入基础 URL: 输入您的 LiteLLM 代理 URL(例如
http://localhost:4000)。 - 输入 API 密钥: 使用任意字符串作为 API 密钥(例如
"sk-1234"),因为 LiteLLM 处理实际提供商的身份验证。 - 选择模型: 选择您在
config.yaml文件中配置的模型名称。
Roo Code 如何获取和解释模型信息
配置 LiteLLM 提供商后,Roo Code 会与您的 LiteLLM 服务器交互以获取可用模型的详细信息:
- 模型发现: Roo Code 向您 LiteLLM 服务器上的
${baseUrl}/v1/model/info发出 GET 请求。如果在 Roo Code 设置中提供了 API 密钥,它将包含在Authorization: Bearer ${apiKey}标头中。 - 模型属性: 对于 LiteLLM 服务器报告的每个模型,Roo Code 提取并解释以下内容:
model_name:模型的标识符。maxTokens:最大输出令牌数。如果 LiteLLM 未指定,默认为8192。contextWindow:最大上下文令牌数。如果 LiteLLM 未指定,默认为200000。supportsImages:根据 LiteLLM 提供的model_info.supports_vision确定。supportsPromptCache:根据 LiteLLM 提供的model_info.supports_prompt_caching确定。inputPrice/outputPrice:根据 LiteLLM 的model_info.input_cost_per_token和model_info.output_cost_per_token计算。supportsComputerUse:如果底层模型标识符与 Roo Code 中预定义的适合“计算机使用”的 Anthropic 模型匹配,则此标志设置为true(参见技术细节中的COMPUTER_USE_MODELS)。
如果您的 LiteLLM 服务器的 /model/info 端点未为给定模型明确提供其中某些属性,Roo Code 将使用默认值。默认值为:
maxTokens:8192contextWindow:200,000supportsImages:truesupportsComputerUse:true(对于默认模型 ID)supportsPromptCache:trueinputPrice:3.0(每 1k 令牌的 µUSD)outputPrice:15.0(每 1k 令牌的 µUSD)
提示和注意事项
- LiteLLM 服务器是关键: 模型、下游提供商(如 OpenAI、Anthropic)的 API 密钥和其他高级功能的主要配置在您的 LiteLLM 服务器上管理。Roo Code 充当此服务器的客户端。
- 配置选项: 您可以使用专用的“LiteLLM”提供商(推荐)进行自动模型发现,或使用“OpenAI Compatible”提供商进行简单的手动配置。
- 模型可用性: Roo Code “Model”下拉菜单中可用的模型完全取决于您的 LiteLLM 服务器通过其
/v1/model/info端点公开的内容。 - 网络可访问性: 确保您的 LiteLLM 服务器正在运行并且可从运行 VS Code 和 Roo Code 的机器访问(例如,如果不在
localhost上,请检查防火墙规则)。 - 故障排除: 如果模型未出现或请求失败:
- 验证您的 LiteLLM 服务器是否正在运行且配置正确。
- 检查 LiteLLM 服务器日志中的错误。
- 确保 Roo Code 设置中的基础 URL 与您的 LiteLLM 服务器地址匹配。
- 确认 LiteLLM 服务器所需的任何 API 密钥都已正确输入到 Roo Code 中。
- 计算机使用模型: Roo Code 中的
supportsComputerUse标志主要与某些已知在工具使用和函数调用任务中表现良好的 Anthropic 模型相关。如果您通过 LiteLLM 路由其他模型,除非底层模型 ID 与 Roo Code 识别的特定 Anthropic 模型匹配,否则此标志可能不会自动设置。